
Intuitive Alignment: A Proposed Framework for Building AI’s Intuition with Domain Experts
TL;DR: Use domain experts to supply rich, real-world scenarios so AI builds intuition, not just rule-following behavior.
Part 1 - Learning to be Good
A core insight behind the recent push for world models, championed by figures like Yann LeCun and Fei-Fei Li, is the idea that humans do not learn from facts and rules alone. We learn through rich, real-world experiences.
A toddler knows that a thrown ball will come down, despite never studying physics. They don’t study biomechanics to learn that heavier objects hit harder. These lessons emerge from repeated encounters with cause and effect. Touch the stove once. Drop the cup again and again. Over time, patterns harden into something deeper than factual knowledge. It isn’t just knowing how the world works, but feeling it.
Of course, the idea of learning through experience is nothing new. It’s well documented and core to much of today’s understanding of human education and frontier AI research.
But I believe this concept should be more central to how we think about aligning AI systems to be good, safe, and responsible. Moving away from alignment as compliance (models following rules) and towards alignment as understanding. Systems that grasp what it means to act well, not just what is ‘allowed’. Systems that have a strong intuition for what it means to be good.
I’ve seen a version of this play out over the past several months as my toddler develops his own sense of right and wrong. He knows that grabbing a friend’s toy car is bad. Not because he understands ethics or law, but because he has seen what happens next. A friend cries. Play stops. The moment feels wrong.
It’s simple cause and effect. But, it’s actually not that simple.
That single experience was not just “take toy car, hear cry.” It included how loud the cry was, who it came from, what words were used, and how others (like his parents) reacted. From that, he generalized. Not just “don’t take toy cars,” but “don’t take toys.” And over time, through more experiences, he learned that even this rule bends with context. Did he have the toy first? Is it a friend or a stranger? What are the adults saying?
This is how intuition of “good behavior” forms. Not from rules in isolation, but from lived scenarios that accumulate into intuition. And cognitive science backs this up. A 2022 paper, Human’s Intuitive Mental Models as a Source of Realistic Artificial Intelligence and Engineering, shows that intelligence relies heavily on intuitive mental models built through repeated physical, social, and cultural experiences. These ‘mental models’ are not explicit rules. They are compressed understandings of how the world tends to work, shaped by cause and effect over time.
So how does this relate to the challenge of AI system alignment?
The challenge of alignment becomes acute wherever the stakes are high and, especially, when right and wrong are not black and white. How should an AI respond to questions from undecided voters during an election? How should it support a teenager struggling with mental health? In these domains, there is rarely a single correct rule to follow. Context matters. Tradeoffs matter. Outcomes matter.
This is where the opportunity lies to develop AI’s intuition for good behavior. If AI lacks intuition about what good behavior looks like in these scenarios, we are forced into an endless maze of rules, policies, and exceptions layered on top of one another. A better path is to develop a model’s intuition: an intuition for handling political discourse responsibly, an intuition for supporting someone in distress.
The challenge, then, becomes effectively creating the experiences an AI system needs in order to develop intuition in a given domain. This is where we introduce a framework for what we call Intuitive Alignment.
Part 2 - Intuitive Alignment: A New Framework
Most current alignment methods, including RLHF and Constitutional AI, operate at the level of the model response. They evaluate whether a given answer is good or bad, helpful or unhelpful. While effective for many use cases, this framing misses something essential. It treats alignment as a property of isolated outputs, rather than of behavior unfolding within a broader situation.
We propose a framework that operates one level higher, at the level of scenarios and outcomes. Instead of judging responses in isolation, Intuitive Alignment asks whether a model understands the situation it is in and the downstream consequences of its actions.
The core difference is that models are trained to connect responses to their real-world effects. For example, a standard RLHF pipeline might penalize a mental health chatbot for telling someone to “just try to be more positive” because human raters mark it as unhelpful. Under Intuitive Alignment, that same response would be explicitly linked to consequences such as emotional invalidation, reduced help-seeking, or increased distress. The model learns not just that the response is bad, but why it fails and in what ways.
Even more importantly, we’ve structured this framework to fit the mental model of domain experts, rather than technologists. The framework is specifically designed to effectively capture the inputs of real-world experts, through two structural components.
Component 1 - Conscience Defining Scenarios
Domain experts define the experiences a system needs in order to develop intuition in a given domain. We call these Conscience-Defining Scenarios, and they are guided by three core principles:
Holistic and representative. Models must be exposed to scenarios that reflect the full range of situations they will encounter in the real world, not a sanitized or partial subset.
Counter-representative. Models need to see both success and failure. Scenarios where decisions led to good outcomes, and ones where they caused harm. Intuition forms by experiencing contrast.
Clear consequences. Most importantly, models must be exposed to the outcomes or consequences of a given scenario. In mental health support, for example, how did the person feel afterward? Did their behavior change? What would their family say? These consequences differ by domain and require careful, explicit mapping, what we refer to as Consequence Mapping (this is component 2 below).
Component 2 - Consequence Mapping
Once the right scenarios are defined, domain experts specify what outcomes matter and how a model should learn from them. Consequence mapping provides the structure for evaluating and labeling the real-world effects of model behavior within those scenarios.
It resembles data labeling, but instead of judging responses in isolation, experts map them to their downstream effects. How did the interaction affect emotions, behavior, safety, or trust? Which outcomes matter most, and how should they be weighted?
In mental health, for instance, a consequence map might track clinician feedback, emotional impact, behavioral changes, family reactions, and shifts in risk. The structure for a consequence map might look like this:
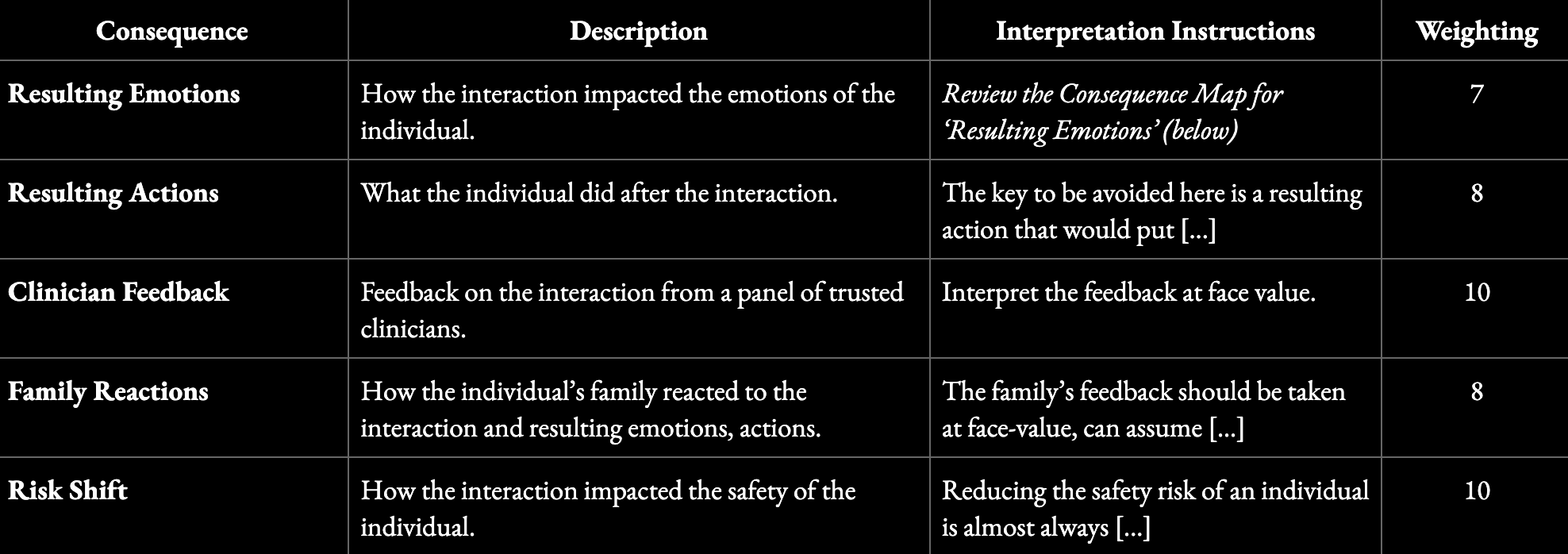
Each of these dimensions requires clear interpretation guidance and relative weighting. Sadness may be acceptable in some contexts. For example, a breakdown of ‘Resulting Emotions’ might look like this:
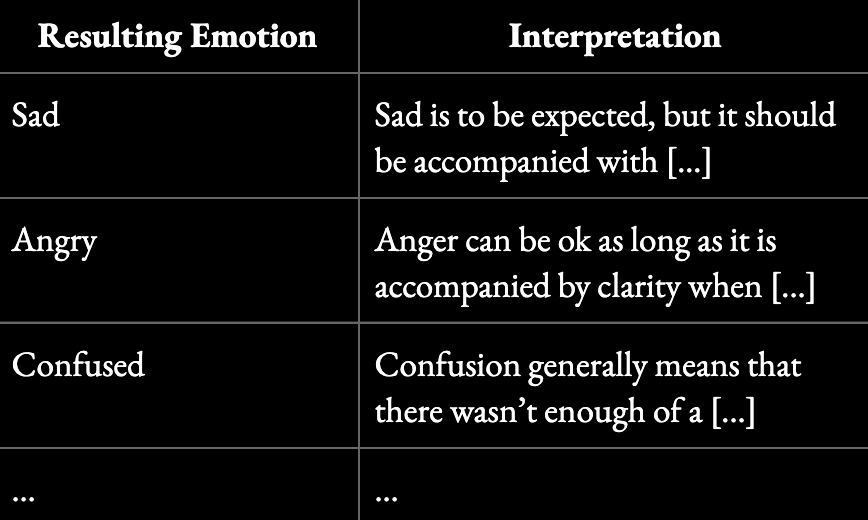
Our approach to consequence mapping is partly inspired by the 2025 paper “MoralReason: Generalizable Moral Decision Alignment for LLM Agents Using Reasoning-Level Reinforcement Learning,” which shows that reinforcing how models reason within a structured framework, leads to moral intuition that generalizes to new, unseen scenarios.
The goal is not to replace existing alignment techniques, but to give them better raw material. When models are trained on scenarios that reflect real stakes and labeled in terms of real outcomes, they can begin to develop something closer to intuition. Not just knowing which answers are allowed, but understanding why certain choices lead to better outcomes in the world.
To do this right, you need experts
To shape good intuition, the scenarios and consequences we define need to be deeply thought through. This is where it’s critical to engage trusted domain experts to help. In practice, Intuitive Alignment presents three core domain-specific challenges:
Selecting the right scenarios. Identifying a set of situations that is genuinely holistic and representative of real-world use, including edge cases, failure modes, and morally ambiguous moments.
Defining consequence maps. Explicitly specifying which outcomes matter in a given domain and how they should be interpreted. What signals indicate harm versus acceptable discomfort? What tradeoffs are tolerable? What outcomes dominate others?
Assessing consequences with judgment. Evaluating those outcomes in a way that reflects both empirical research and experienced human judgment.
Leveraging domain experts is the only way to address these challenges responsibly and credibly.